Create a Data Profile
There are two ways to generate a data profile:- As part of the Mezmo Flow onboarding process or the Log Volume Reduction pipeline creation process.
- Through the Data Profiler Processor, which you can set it up as a component within a Pipeline that you build yourself.
View the Data Profile
Once a Data Profile has been generated for the Source, you can access it through both the Processor itself, and the navigation in the Mezmo Web App.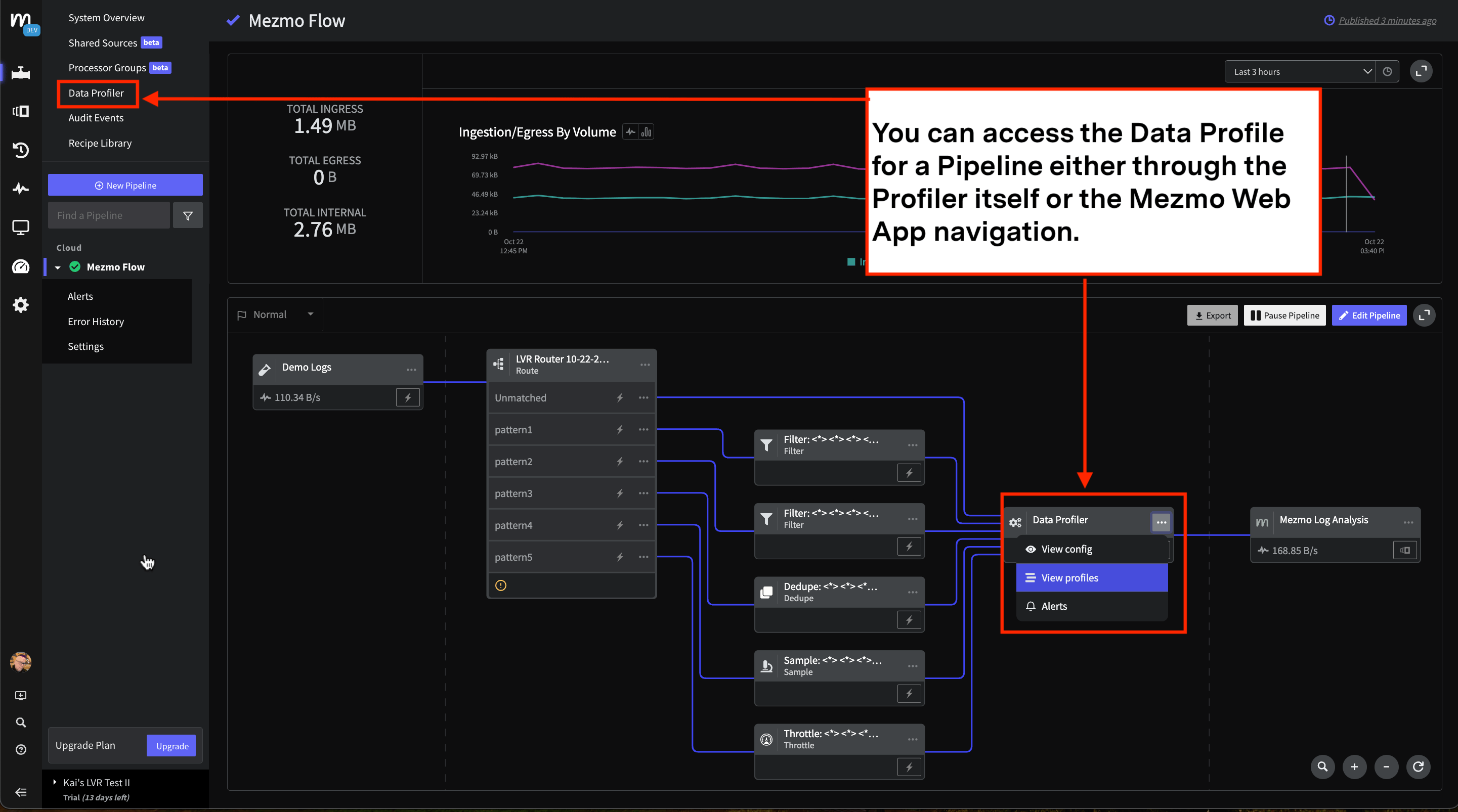
Screenshot showing how to view a data profile for a pipeline
Message Templates
The Message Templates section provides a report of log patterns discovered in the data. This enables you to understand how much specific log patterns contribute to the overall source volume, expressed as a percentage of the total data volume. With this information, you can determine if the logs matching the pattern are important for investigation and troubleshooting , or if they are low-value logs that can be archived and don’t need to be sent to your observability platform. The columns in the Message Templates section, which are all sortable, include:- Apps, which shows the number of apps that produced these log patterns. You can hover on the number to see the name of the app(s) that produced the log pattern.
- Template shows the tokenized log lines with variables that change from message to message, such as IP or Host, and are replaced by
<*> - Total Lines shows the number of log lines that match this pattern
- Total Line Size shows the sum of all the log lines that match this pattern
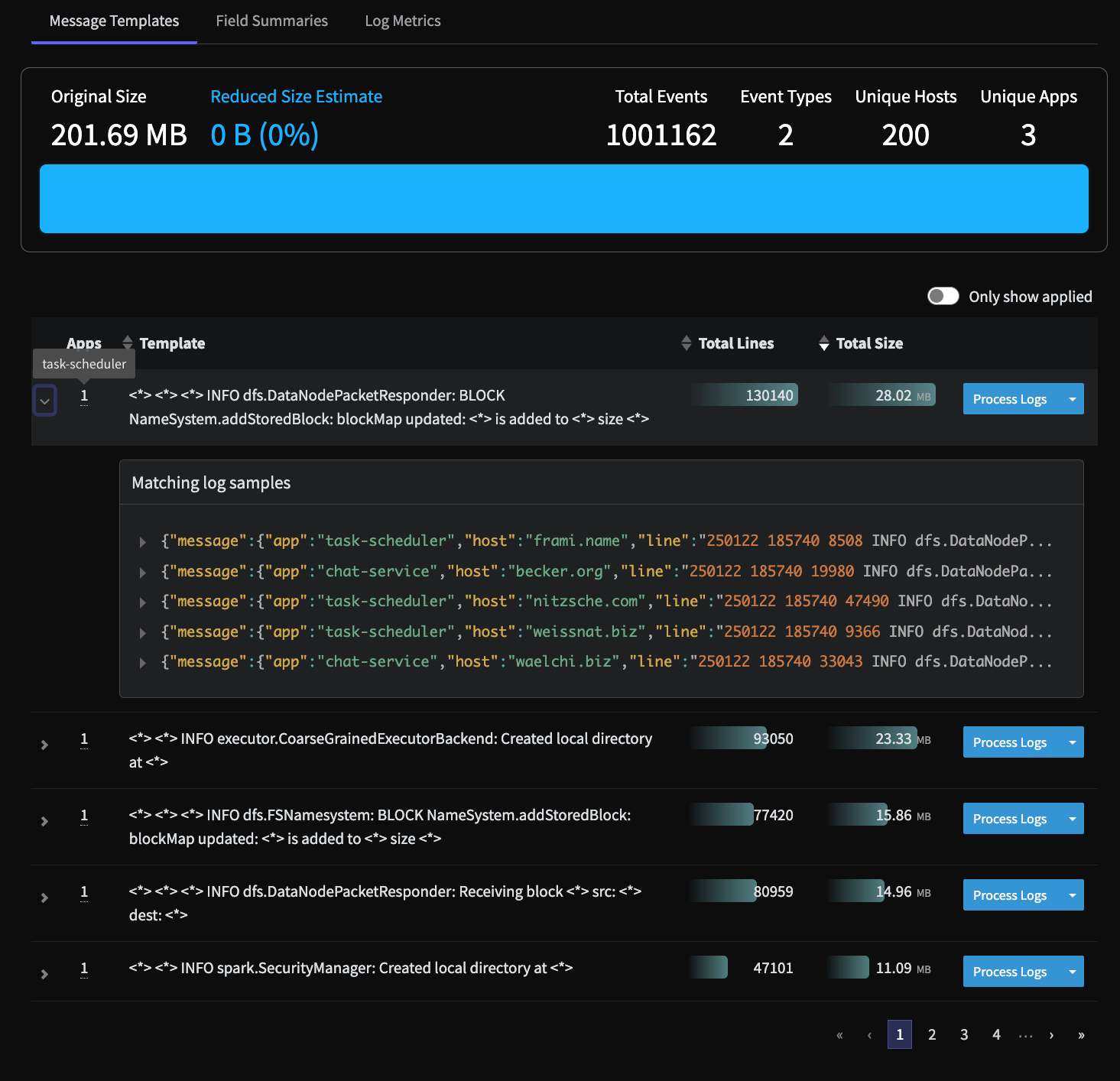
The Message Templates discovered by the Data Profiler, including the app that generated the selected template, and matching log samples
Field Summaries
This is an experimental feature that is still in development. For access to this feature, reach out to your Customer Support Manager or support@mezmo.com.
You can also apply Processors based on Field or Field Value. At the Field level, you can only select Remove Field. At the Field Value level, you can apply Processors such as Filter, Sample Processor, Dedupe Processor, and Throttle Processor. If you remove a field at the Field level, the Field Value processors are disabled because they are mutually exclusive.
This table describes the value displayed based on the value type:
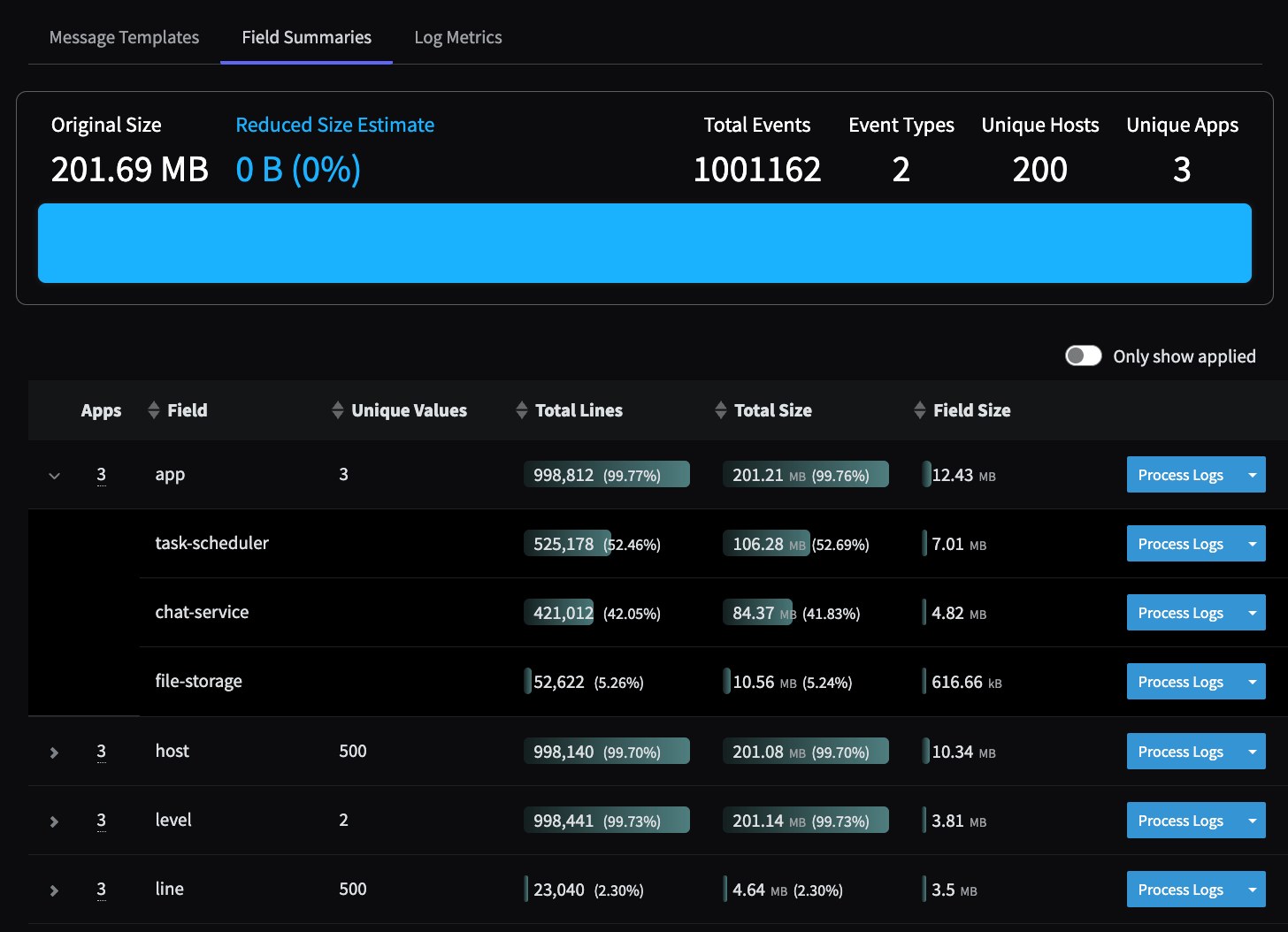
Field Summaries generated by the Data Profiler, showing the Unique Values associated with the app field.
Log Metrics
The Log Metrics section provides a report of the profiled logs categorized by App, Host, Log Level and Log Type: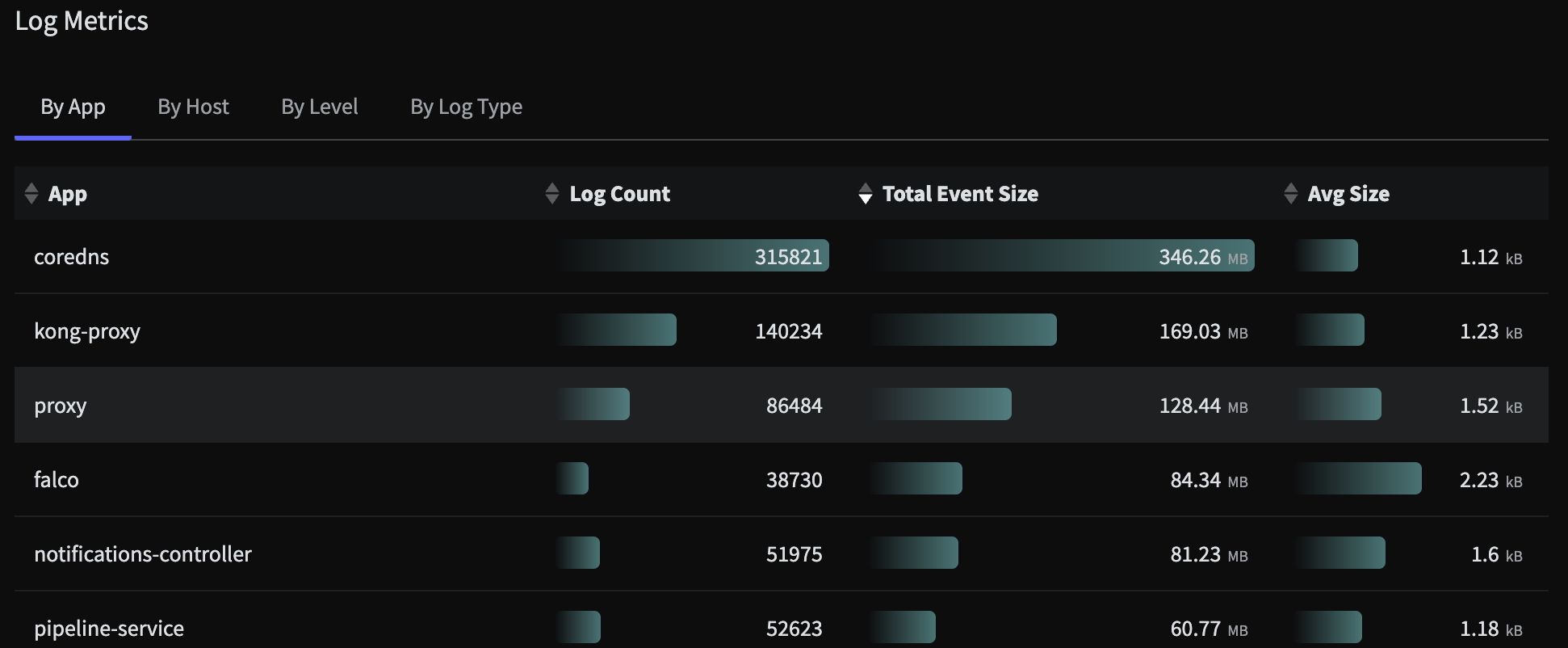
The Log Metrics analysis for an HTTP Shared Source