If you run into any issues or have feedback on either the workshop or Pipeline, please reach out to us at support@mezmo.com.
Pipeline Architecture
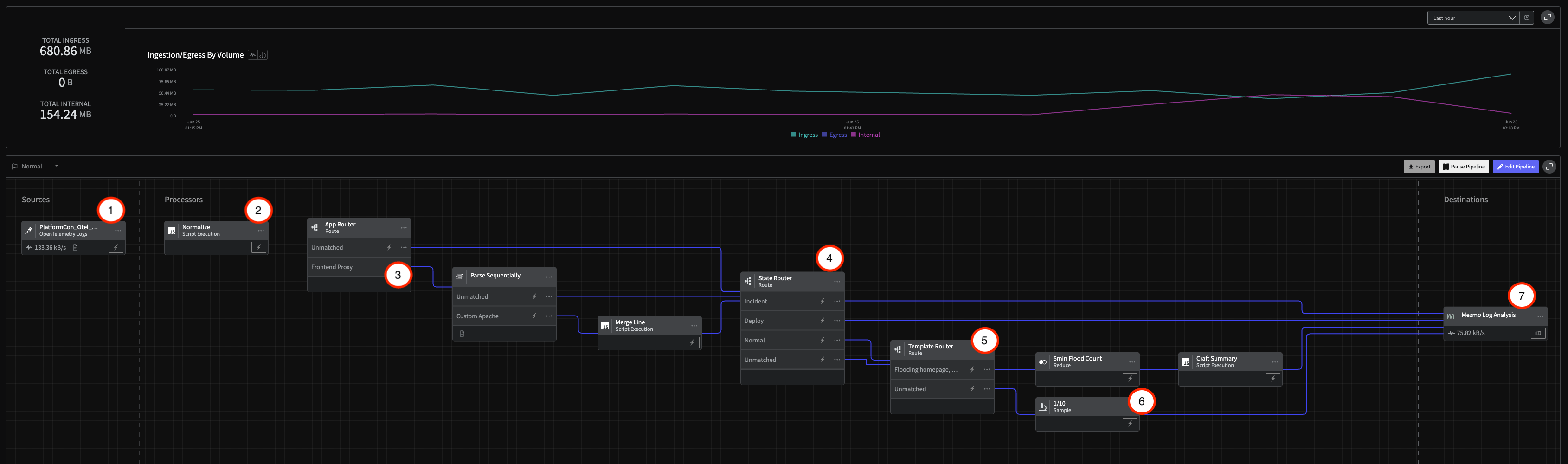
1 - Create the Pipeline and Add the Source
- In the Mezmo Web app, click New Pipeline and name it
Log Handler. - In the Pipeline Map, click Add Source, then select the OpenTelemetry Log source you created in Step 2.
2 - Add State Variables
A responsive pipeline changes its functioning based on detection of state changes. For this example, you will use the Script Execution Processor to add variables to the data that indicate the operational state of the pipeline.- Click the
...menu in the upper-right corner of the OpenTelemetry Log source. - Select Add Node > Add Processor > Script Execution.
- Connect the processor to the OTel Log source.
- Copy and paste this script into the Script field in the processor configuration panel, then click Save.
In addition to adding state variables to the data, this script also normalizes the data so it is more compatible with Mezmo Log Analysis.
3 - Create the Custom Apache App Logs Parsing Processor Chain
As you saw in the Data Profile from step 4, the OTel data being sent byfrontend-proxy is an unparsed, custom format defined by the OpenTelemetry demo. This data needs to be send through a specialized processor chain that contains a Route Processor, a Parse Sequentially Processor that includes a Grok parser, and a Script Execution Processor to structure it and make it more easily searchable.
Route Custom Apache App Data
- In the Pipeline Map, click Add Processor, and select Route.
- Connect the Route processor to the Script Execution processor.
- Enter these configuration options for the processor, then click Save.
Parse the App Data
- In the Pipeline Map, click Add Processor, and select Parse Sequentially.
- Enter these configuration options for the processor, then click Save.
- Connect the Parse Sequentially processor to the
Frontend Proxyoutput of the Route processor.
Merge Custom App Data Lines
In this case, the Script Execution processor is used to preserve the original line for the custom app data.- In the Pipeline Map, click Add Processor and select Script Execution.
- Copy and paste this script into the Script field.
- Click Save, then connect the Script Execution processor the to the
Custom Apacheoutput of the Parse Sequentially processor.
4 - Route Data Based on State
The next Route processor in the chain will route data based on the operational state. For the Incident and Deploy states, the data is sent directly to Mezmo Log Analysis, while Normal or unmatched data is sent through a final processing chain to aggregate and reduce the volume of the custom app log events.- In the Pipeline map, click Add Processor, and select Route.
- Enter these configuration options for the processor, then click Save.
5 - Create the “Flooding Homepage” Reduction Processing Chain
Duringnormal conditions, the log data contains a high volume of “homepage flooding” logs that convey little information in their unprocessed state. One technique to deal with noisy data like this is to convert events to metrics. In this case, the data is routed to a Reduce Processor, which will provide a count of the events over five minutes to Mezmo Log Analysis, and then sent to a Script Execution process to generate a summary message.
Route the Data
- In the Pipeline Map, click Add Processor, then select Route.
- Enter these configuration options for the processor, then click Save.
- Connect the
NormalandUnmatchedroutes of the State Router to the input of this Route processor.
Reduce the Data
- In the Pipeline Map, click Add Processor, then select Reduce.
- Enter these configuration options for the processor, then click Save.
Add a Summary Message
Finally, we will convert the output into a summary message using the following configuration6 - Sample Normal State Logs
For theunmatched logs that pass through the Router, you only need to sample a small proportion of them while the pipeline is in the normal operational state. For this example, you will add a Sample processor that will sample every 1 in 10 of the unmatched logs.
- In the Pipeline Map, click Add Processor, then select Sample.
- Enter these configuration options for the processor, then click Save.
7 - Connect to Mezmo Log Analysis
Finally, we will send all of this data into Mezmo Log Analysis. Because of our earlier work normalizing data in Step 3, we can simply add a final Destination to all nodes (including theIncident and Deploy paths).
- In the Pipeline Map, click Add Destination.
- Select Mezmo Log Analysis, enter these settings, then click Save.
- After saving the configuration, connect the Log Analysis destination to the outputs of the other processors as shown in the architecture schematic.
7 - Deploy the Pipeline
To activate the pipeline, click Deploy in the upper-right corner of the pipeline map.8 - Initiate State and Grab State ID
Our final step is to initiate and grab the state ID for the pipeline in Normal operation. Click the State menu in the upper-left corner of the active pipeline, change the state toIncident, then change it back to Normal.
Now that has been initiated, you will need get the Log Handler pipeline’s ID (found in the URL at app.mezmo.com/ACCOUNT_ID/pipelines/PIPELINE_ID) along with a Pipeline API Key here. Then, modify the following script with both that PIPELINE_ID and Pipeline API Key
STATE_ID for later. You will find it in the operational_state’s data packet, which should look something like this:
9 - View In Mezmo Log Analysis
Navigate to Log Analysis and view the incoming data. In particular, if you used thetag above you can simply search for tag:otel-demo.
First, look for the aggregated data by searching for tag:otel-demo "flooded homepage". Notice that instead of raw lines like we saw in the Profile, we now have an aggregated message to watch saving tens of thousands of log lines.
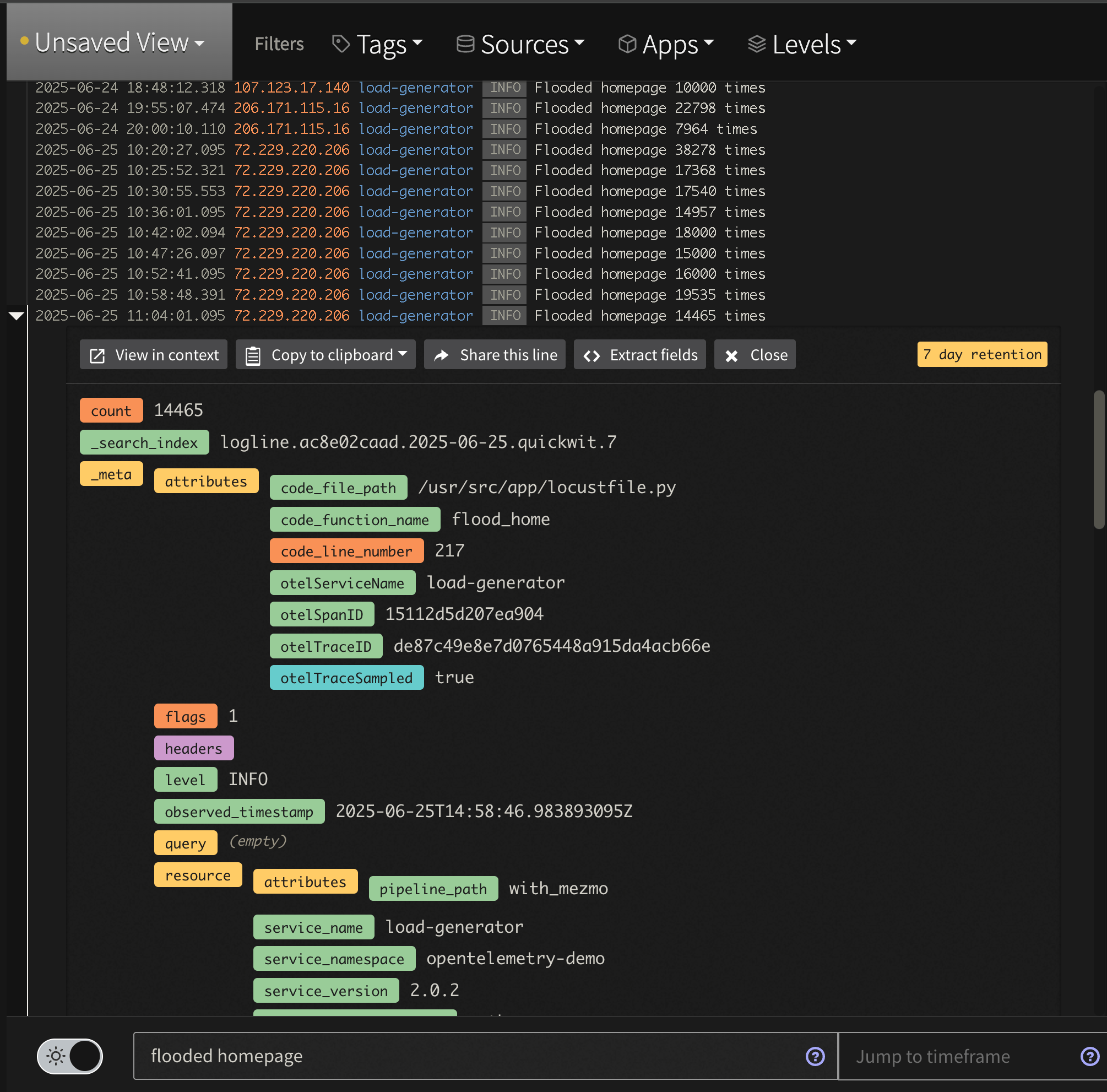
Log Analysis Flooded Log View
tag:otel-demo app:frontend-proxy. While logs are displayed nicely in the Log Viewer, you can expand a line and see all the nested structure that is easily searchable. For instance, to see all 2xx responses enter the query tag:otel-demo app:frontend-proxy resp_code:(>=200 AND <300)
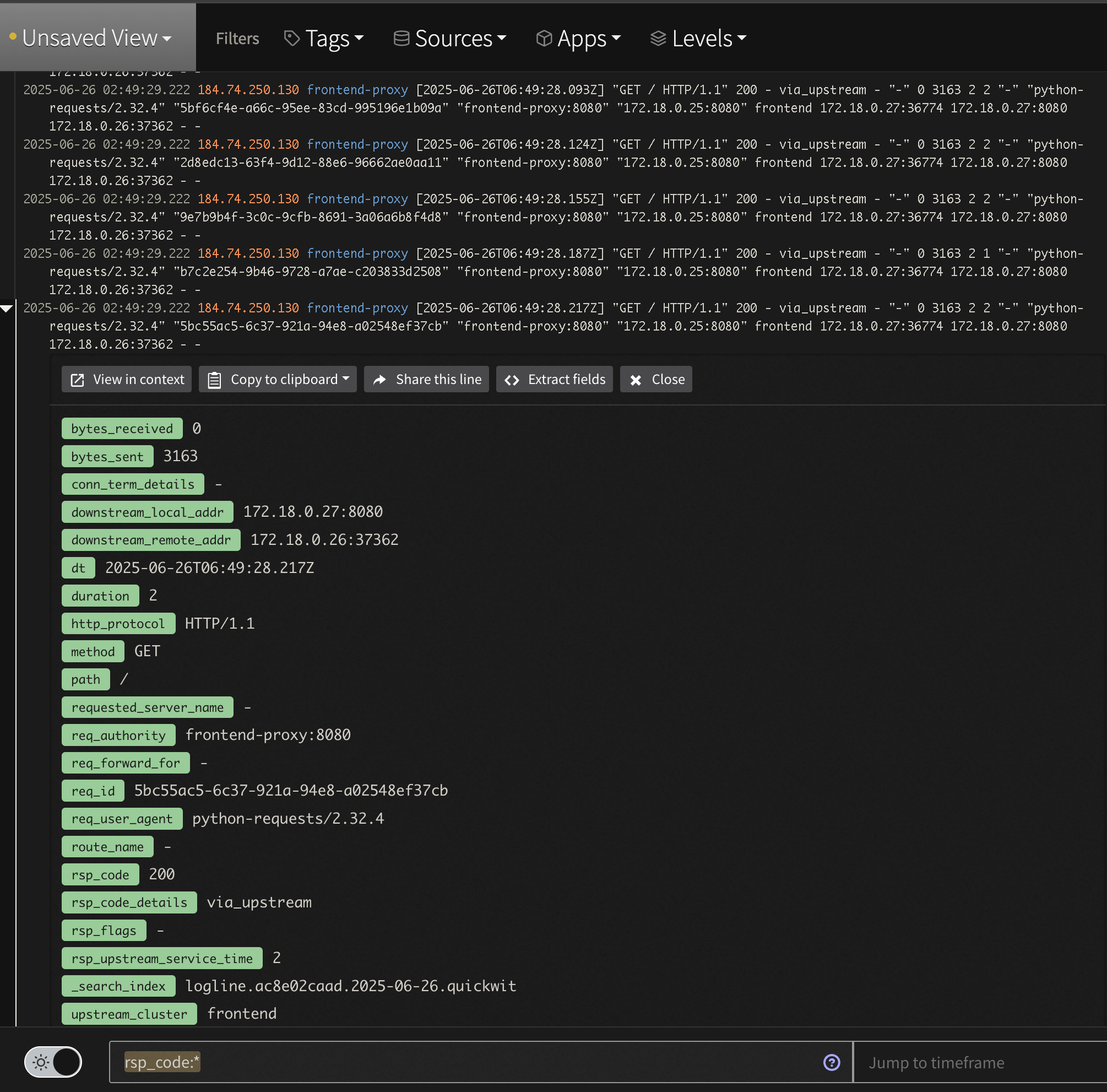
Log Analysis Custom Apache Log View