Visualizing log data provides insights into application availability, performance, resource usage, and errors at a glance. It allows teams to generate statistics, identify trends, and detect patterns in operational behavior. The result is a better overall view of your infrastructure.
This article will cover some real scenarios and how to use graphs to understand trends and troubleshoot.
Detecting Errors
If errors are not detected, they can have serious consequences. Logs help us understand the cause and impact of errors, including when they happened, what happened, and what needs to be done to fix them. This information is useful for understanding and fixing errors.
This graph shows log lines that contain the word error over time.

The graph shows the count of logs that contain the word error over a certain period of time.
You can see a few errors followed by periods of stability. A significant spike occurs shortly after 12pm, which is roughly when the application restarted. We can view the individual log events by clicking on the spike and selecting Show Logs. You'll be taken to the Log Viewer. There you'll see all log lines from that date and time.
To investigate further, select and individual log line and click View in Context, to see the log lines surrounding the error. In this example, someone or something repeatedly tried to log into the PostgreSQL database as an administrator with the wrong credentials. PostgreSQL to logged an error each time the user was denied.
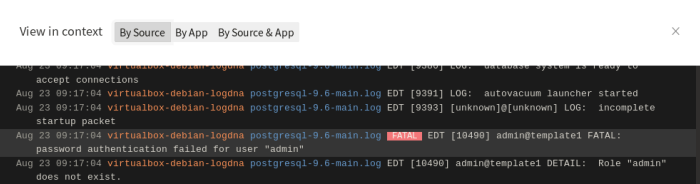
View log lines in context to see lines surrounding the log line
Detecting Unusual Behavior
Log volume is a basic but important metric. Sudden changes in log volume can indicate errors, software or hardware failures, performance problems, or problems with the logging infrastructure itself. Restarting a server naturally results in a surge in log volume, which we can easily detect by charting log volume over time. However, any other surges could indicate larger problems. As shown below, our virtual machine experienced two major spikes in log volume followed by a period of relative inactivity:
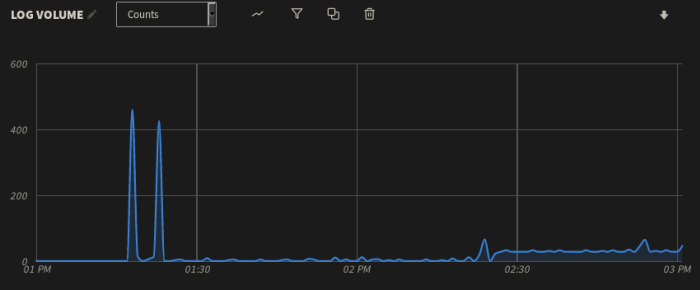
Graph of a virtual machine showing two log spikes
To learn more about the cause of these spikes, we can click on the peak of each spike and use the Show Logs button to view the logs in the Mezmo dashboard. As it turns out, the first spike is the result of logs generated during the virtual machine’s startup process, which is expected. The second spike, however, consists entirely of logs generated by the popularity-contest service, which records statistics about the software installed on the system. Although popularity-contest only ran for a short time, it generated almost an equivalent volume of log data as the startup process.
To get a better idea of the impact that popularity-contest had on log volume, we can add a new plot to the total volume chart and filter the app field to only show events originating from popularity-contest:
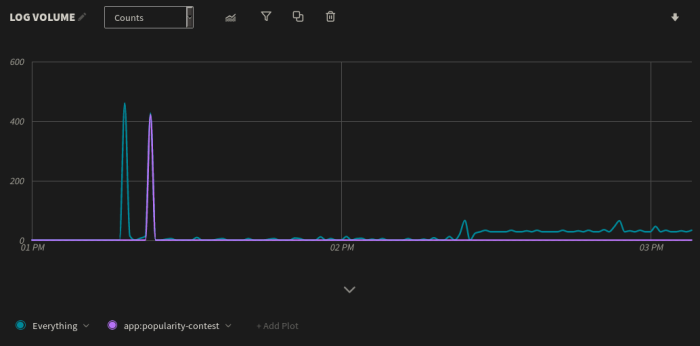
Graph showing log spikes filtered by app name to determine which apps or processes were casing the spikes
Investigate With Histograms
You may want to count log volume by a specific field, such as the log-level, host, application, or a custom tag. For example, plot out log volume based on the service that generated each event (stored in the app field). In the example, you can see, the popularity-contest service generates the greatest number of messages, followed by the virtual machines syslog service and daemon log.

Histogram showing log volume compared across apps.
If we create a histogram using the level field instead of the app field, we see that most of these messages are either info or debug logs. There are still a few warning, error, and fatal logs to investigate.
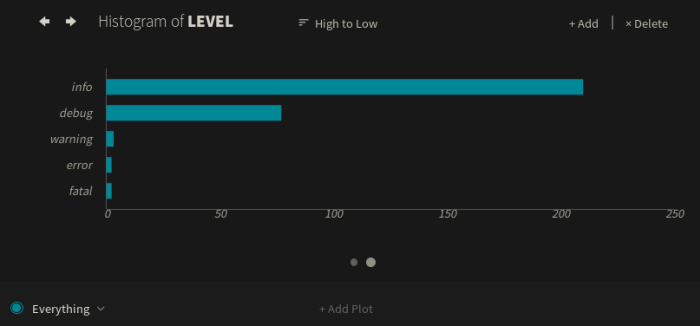
Histogram showing log volume by type
We can click on the popularity-contest spike and use the Show Logs button to view log entries originating from the service.

Log viewer showing logs from the service popularity-contest. These logs are related to the log spike.
The solution to this problem was to disable the popularity-contest service. This resulted in slightly faster startup times, less network traffic, and lower log volumes.
Analyzing Changes in Performance
We can use visualization tools to track application performance metrics, including response times, response sizes, and request volumes. For example, our web application logs the size of each response in bytes. After the restart, the average response size started significantly higher than usual. Shortly after, the response size fell to a low and steady average.
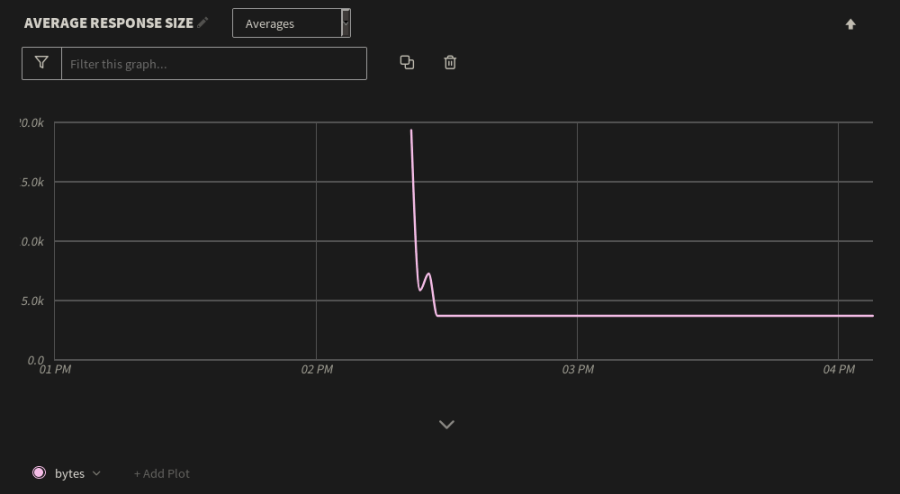
Average response time of a web application. There is a big spike, the normalizes.
Using percentiles, we can track metrics that fall far outside of the average, such as unusually large responses. We can do this in Mezmo by changing the metric measured from Averages to 99th Percentile, which displays the top 1% of response sizes over the same period of time:
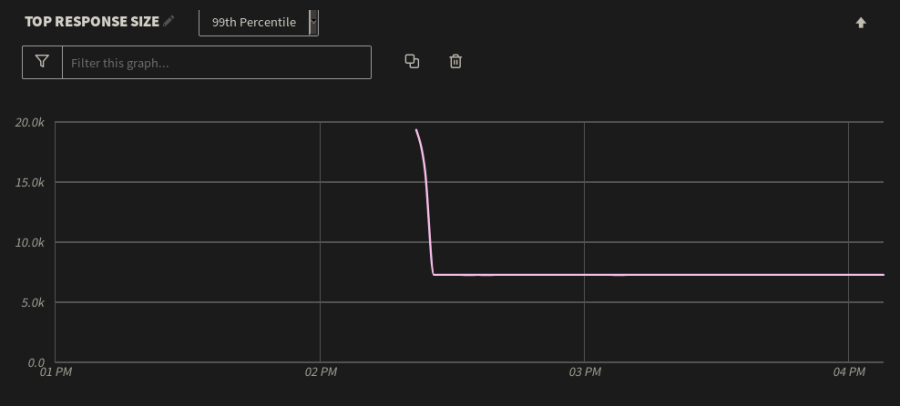
The web application spike is charted to the 99th percentile to display the top 1% of response sizes over the same period of time. The spike was not normal.
You can see the log messages for each data point on the chart. For example, the large responses were caused by users having to re-cache an asset-heavy page after the application was restarted. Once users stopped caching this page, the extremes fell to within 2–3 KB of the average. We can mitigate this by reducing the size of the page, updating the web server caching configuration, or by placing the server behind a content delivery network.