Key Deployment Considerations
- Data ingestion: how much data are you planning to send through Edge?
- Processing requirements: are you planning to do any special processing, such as regex, deduplication, or other custom scripts?
- Destination targets: where are you planning to send the data?
Deployment Model
Mezmo Edge uses a hybrid cloud deployment model. When the Edge satellite nodes are deployed they automatically contact the Mezmo Cloud APIs. For this reason, Edge currently requires access to the wide area network (WAN) to function.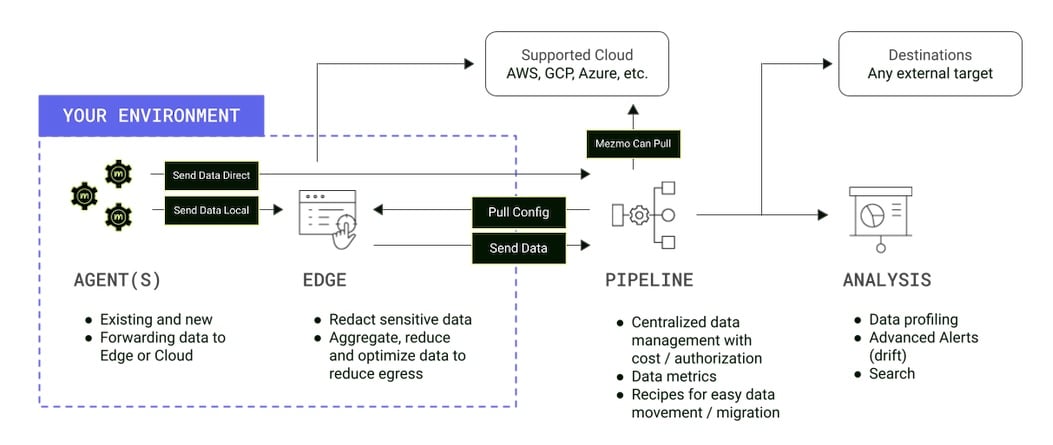
Resource Requirements
These numbers are intended for general guidance. Resource requirements depend on many factors. Use the deployment considerations in combination with the sizing guidance to estimate actual sizing.Sizing
These numbers are effective averages to use in approximation. Your individual event sizes may. Estimations in events per second (EPS) are conservative. These specifications are based on the guidelines published in the Vector documentation. Assumptions- Each vCPU is a standard ARM processor without hyper-threading
- Throughputs are purposefully conservative